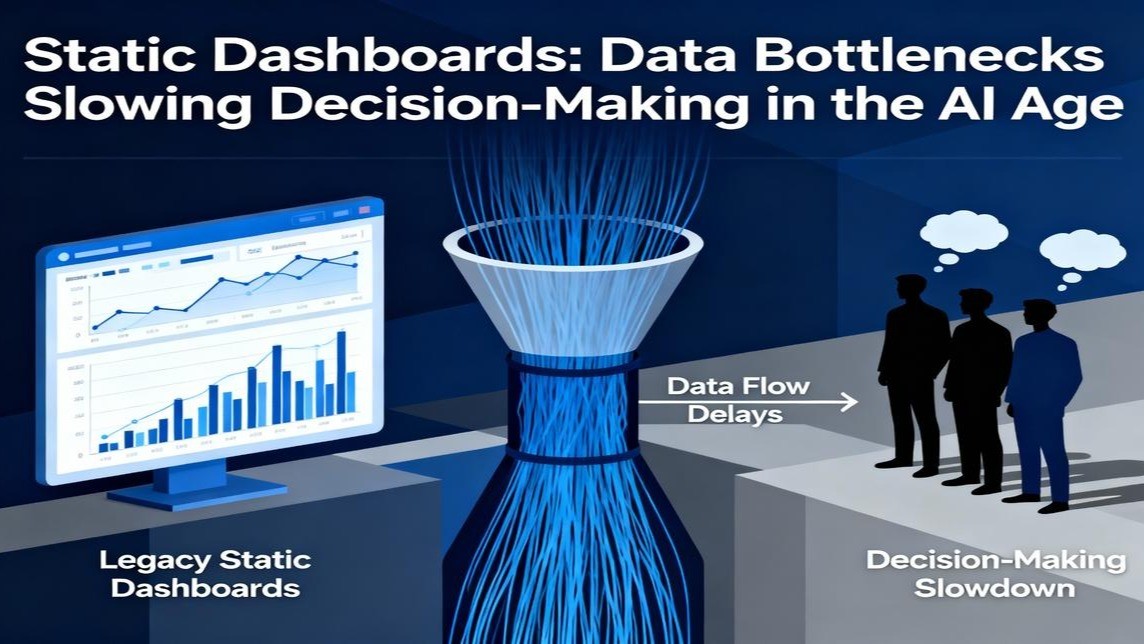
Introduction: The AI Value Paradox—Why Most Initiatives Fail to Scale
The enterprise landscape is saturated with the promise of Artificial Intelligence. A 2024 Forrester survey reveals that 67% of AI decision-makers plan to increase their investment in generative AI within the next year, signaling a powerful and sustained push toward embedding intelligence into core business functions. Yet, a stark and costly reality check tempers this enthusiasm. Despite the buzz and the budgets, a staggering 70-80% of AI projects fail to move beyond the proof-of-concept (POC) stage and deliver tangible business value. This chasm between ambition and achievement has created an "AI Value Paradox": while individual employees report productivity gains from using readily available AI tools, organizations are not seeing corresponding improvements in corporate balance sheets or macroeconomic productivity metrics.

The central argument of this report is that this widespread failure is not a flaw in the AI algorithms themselves—which are more powerful and accessible than ever—but a direct consequence of a systemic underinvestment in, and misunderstanding of, the data foundation upon which these algorithms depend. Success in the modern AI era is, as one analysis puts it, "a data game, not a code fest". Poor data quality and availability consistently rank as the number one obstacle to AI implementation and a primary driver for abandoning generative AI projects after the initial POC phase. A recent Harvard Business Review Analytic Services survey underscores this disconnect: while 65% of organizations consider AI adoption a strategic priority, 54% do not believe they have the requisite data foundation, and a mere 10% feel "completely ready" to adopt AI. This isn't merely a technical gap; it is a profound failure of strategy and governance.
This article provides a strategic guide for executives and consultants tasked with navigating this complex environment. It will first explore the revolutionary shift from a model-centric to a data-centric mindset, which redefines the source of competitive advantage in AI. It will then dissect the anatomy of AI project failure, quantifying the high cost of ignoring "data debt." Following this diagnosis, the report will provide a C-suite-level comparison of modern data architectures—data lakes, lakehouses, and the data mesh—framing the choice as a strategic business decision. It will then outline the imperatives of modern data governance and the transformative power of data pipeline automation in accelerating time-to-value. Finally, it will present compelling, real-world evidence of how a robust data foundation translates directly into quantifiable financial returns, proving that the hidden key to enterprise AI success lies not in the model, but in the data.
1. The Data-Centric Revolution: A Strategic Shift from Models to Data

For the past decade, the prevailing approach to improving AI performance has been model-centric. In this paradigm, the dataset is treated as a fixed asset, and the primary focus of research and engineering is to iteratively improve the model's code and architecture to better handle noise and extract patterns from that static data. This approach, which dominates academic research, has yielded tremendous algorithmic progress.
However, it is proving increasingly insufficient for real-world enterprise applications, where data is not a pristine, curated benchmark but a messy, dynamic, and inconsistent reflection of complex business operations. As powerful model architectures, such as transformers, become increasingly commoditized and accessible through open-source projects and cloud APIs, the true source of sustainable competitive advantage is shifting. It is no longer the cleverness of the algorithm that provides a defensible moat, but the unique, high-quality, and proprietary data an enterprise possesses and its ability to systematically engineer that data for intelligence.
Defining Data-Centric AI (DCAI)
This strategic realignment has given rise to the DCAI, a paradigm championed by machine learning pioneer Andrew Ng. DCAI is formally defined as "the discipline of systematically engineering the data used to build a successful AI system". This represents a fundamental inversion of the traditional approach. In a data-centric world, the model architecture is held relatively fixed, and performance gains are achieved by systematically improving the quality and quantity of the data fed into it. This philosophy reframes data improvement not as a one-time "preprocessing" step to be completed before the "real" modeling work begins, but as an integral, iterative component of the entire AI lifecycle—from development and deployment through to ongoing monitoring and maintenance. It is a continuous process of engineering data excellence.
The successful implementation of a data-centric strategy requires a fundamental shift in how organizations operate, moving beyond technology to address core processes and human collaboration. This is not simply a technical project to be delegated to a data science team; it is a change management initiative that demands executive sponsorship and a new, cross-functional operating model. Activities at the heart of DCAI, such as collaborating with subject matter experts (SMEs) to define product defects, achieving consensus on labeling standards across different business units, and standardizing workflows, are about redesigning how people work together. This echoes a common reason for AI failure: treating AI as a technology deployment rather than a business transformation initiative. A Chief Data Officer in a data-centric organization must therefore act as much as a diplomat and educator as a technologist, building bridges between technical teams and business domain experts to ensure that data becomes a shared, enterprise-wide asset.
Key Principles of a Data-Centric Approach
The transition to a data-centric methodology is guided by a set of core principles that transform data management from an artisanal craft into a disciplined engineering practice.
- Systematic Data Engineering: The first principle is to move away from ad-hoc, often painstaking data work that relies on the "luck or skills of individual data scientists". Instead, the goal is to establish reliable, efficient, and repeatable processes and tools for building, maintaining, and evaluating datasets. This means treating the creation and curation of a dataset with the same rigor as software development, including practices like versioning, documentation, and automated testing.
- Focus on Data Quality and Consistency: The most critical driver of model performance in a data-centric approach is the consistency of the data, particularly its labels. Ambiguity is the enemy of AI. For example, in a manufacturing setting, if one well-trained expert labels a pill as "chipped" while another labels a similar defect as "scratched," the AI system receives confusing signals that degrade its accuracy. A data-centric approach systematically addresses this by creating clear, documented labeling instructions with examples of borderline cases, using multiple labelers to identify and resolve inconsistencies, and directly involving domain experts—such as cell biologists labeling cell images—to ensure labels reflect ground truth.
- Iterative Data Improvement: Rather than collecting as much data as possible, the focus shifts to targeted improvement. A key workflow involves training a baseline model and then using error analysis to identify specific subsets or "slices" of data where the model performs poorly. The team can then focus its efforts on improving that specific data subset. This improvement can take many forms: relabeling inconsistent examples, augmenting the dataset with more examples of underrepresented edge cases, or even strategically removing noisy or irrelevant examples. As Andrew Ng notes, "More data is not always better!". This iterative loop of training, analyzing errors, and improving data is the engine of a data-centric practice.
The Business Case for DCAI
The strategic imperative for adopting a data-centric approach is particularly acute for industries outside of the consumer internet giants. Sectors such as manufacturing, healthcare, government technology, and financial services often operate with smaller, more specialized, and highly contextual datasets. The big-data "recipe" of collecting massive user-generated datasets and applying complex models does not translate to these environments. A manufacturer needs a custom model trained on images of its specific products to detect defects; a hospital system requires a custom AI trained on its unique electronic health record data.
For these organizations, the key to unlocking AI's value is the ability to make models work with "small data, with good data, rather than just a giant dataset". This is precisely what DCAI enables. It provides the tools and methodologies to systematically improve these smaller, domain-specific datasets to a level of quality where they can power highly accurate, custom AI systems. This approach is seen as the only viable path to successfully executing the tens of thousands of stalled, high-value AI projects—estimated at $1 million to $5 million each—that currently exist across these industries. By shifting the focus from endlessly tweaking models to systematically engineering data, DCAI makes AI more accessible and effective, accelerating deployment and improving accuracy for a much wider range of organizations.
2. The Anatomy of Failure: Quantifying the High Cost of Data Debt
The long-standing computing adage "Garbage In, Garbage Out' (GIGO) remains the most succinct explanation for AI project failure. However, this simple phrase belies the complex and compounding nature of the problem. The consequences of poor data readiness can be more accurately framed as a form of "data debt"—a hidden liability within the organization's data assets that accrues "interest" over time. This debt makes every subsequent AI initiative more costly, more time-consuming, and more likely to fail. This section moves beyond the GIGO principle to dissect the specific failure modes through which this data debt manifests, revealing the tangible business risks and operational drags that sabotage AI ambitions.
These failure modes do not exist in isolation; they are deeply interconnected and create a negative feedback loop that exponentially increases the cost of AI development. For instance, the existence of data silos makes it nearly impossible to get a complete, enterprise-wide view of data, which in turn dramatically increases the likelihood of training a model on a dataset with hidden, systemic biases. A model trained on such flawed data will inevitably struggle to generalize to real-world scenarios. When deployed, this poorly generalized model will be acutely sensitive to data drift, as it never learned the true, underlying patterns in the first place.
This compounding effect explains why many organizations become trapped in the "pilot trap". The initial cost and effort required to overcome the foundational data debt for a single project are so immense that there is no organizational appetite to repeat the painful process. The marginal cost of launching the second and third AI projects becomes progressively higher, not lower, because the underlying debt is never paid down. To break this cycle, organizations must understand and address the distinct, yet intertwined, failure modes that constitute their data debt.
Failure Mode 1: Embedded Bias and Flawed Decisions
AI models are powerful learning machines, but they learn from the data they are given. If that data reflects historical biases or underrepresents certain populations, the model will not only replicate those flaws but amplify them at scale. This leads to discriminatory and inequitable outcomes. High-profile examples include facial recognition systems that disproportionately misidentify people of color and healthcare AI models trained primarily on data from white patients, leading to inaccurate diagnoses for other demographic groups.
This is far more than an ethical lapse; it is a significant business risk. Biased AI systems can lead to flawed decision-making, such as an AI-powered hiring tool that systematically filters out qualified candidates from certain backgrounds due to correlations in the training data rather than skill. The consequences include substantial legal and regulatory jeopardy, with non-compliance resulting in hefty fines under regulations like GDPR. Furthermore, such failures can cause irreparable reputational damage and erode the trust of customers, employees, and partners.
Failure Mode 2: Poor Generalization and the Pilot Trap
A common scenario in AI development is a model that performs exceptionally well during the proof-of-concept phase but fails when deployed in a real-world production environment. This failure to generalize stems from several data-related issues. One is overfitting, where the model essentially "memorizes" the noise and specific quirks of the training data instead of learning the underlying patterns. This is particularly common when data quality is poor, as the model becomes overly specialized in recognizing past anomalies rather than adapting to new, dynamic situations.
Another cause is edge-case neglect. The training data may be clean but not fully representative of the real world, lacking examples of rare but critical scenarios. An autonomous vehicle, for example, might perform perfectly in normal conditions but fail dangerously when encountering an unusual road obstruction not present in its training data. This inability to handle edge cases can lead to financial losses, safety risks, and a loss of customer trust. The result of poor generalization is the "pilot trap": promising projects demonstrate initial success in a controlled lab setting but cannot be scaled, leading to wasted resources, project cancellations, and growing skepticism about AI's true value within the organization.
Failure Mode 3: Operational Paralysis from Data Silos and Inconsistency
For most enterprises, data is not a unified asset but a fragmented collection of disconnected systems. This problem of "data silos" means that critical information is trapped within different departmental databases—such as a CRM, a billing system, and a support platform—that are often incompatible. This fragmentation is compounded by rampant data inconsistency. A single customer might appear with slight variations in each system, or critical data points like dates and currency may be stored in multiple, mismatched formats.
This operational chaos creates a state of paralysis for AI initiatives. Data science teams report spending up to 80% of their time and effort on "data wrangling"—the tedious process of finding, cleaning, and integrating data from these disparate sources—rather than on building and refining models. This massive inefficiency dramatically slows down project velocity and inflates costs. In many cases, the data problems are so severe that they sabotage the model before it can even be trained, as faulty patterns are learned from inconsistent or duplicated records.
Failure Mode 4: Data Drift and Model Decay
AI models are not static artifacts; their performance is intrinsically tied to the data they process. A critical and often overlooked failure mode is data drift, which occurs when the statistical properties of the data a model encounters in production begin to diverge from the data it was trained on. This can happen for many reasons: customer behaviors and preferences change, new products are introduced, or external market conditions shift.
When data drift occurs, the model's predictive accuracy degrades over time, a phenomenon known as model decay. A fraud detection model trained on historical data may fail to recognize novel fraudulent tactics, or a demand forecasting model may become inaccurate after a sudden shift in consumer spending patterns. Without a robust data foundation that includes continuous monitoring and automated pipelines for retraining models with fresh data, the initial investment in building the AI system is wasted. The model becomes a depreciating asset, making increasingly unreliable predictions that can lead to poor and costly business decisions.
3. Architecting for Intelligence: A C-Suite Guide to Data Lakes, Lakehouses, and the Data Mesh

The choice of a data architecture is not a purely technical decision to be delegated to the IT department. It is a fundamental business decision that dictates an organization's future capacity for agility, scalability, and effective AI governance. The architecture determines how data is stored, accessed, managed, and ultimately, transformed into intelligence.
An organization's architectural philosophy is a direct reflection of its cultural readiness for AI, revealing its approach to control, collaboration, and accountability. An enterprise that defaults to a purely technical solution for data storage without addressing the underlying governance and cultural challenges is likely unprepared for the deep, cross-functional collaboration that scalable AI demands. Conversely, an organization that can successfully implement a decentralized, domain-driven architecture has likely already solved many of the organizational and cultural hurdles that sink most AI initiatives. Therefore, evaluating which architecture an organization could realistically support today provides a powerful diagnostic of its true AI maturity.
Architecture 1: The Centralized Data Lake
The data lake emerged as a response to the limitations of traditional data warehouses, offering a centralized repository to store vast amounts of raw data—structured, semi-structured, and unstructured—in its native format. Built on cost-effective cloud object storage like Amazon S3 or Azure Blob Storage, it employs a "schema-on-read" approach, providing immense flexibility by deferring data structuring until the moment of analysis.
- Promise for AI: For AI and machine learning, the data lake's primary advantage is its ability to house the massive, diverse datasets required to train complex models. It provides a single, scalable storage layer for everything from customer transaction logs to IoT sensor data and social media feeds, making all potential training data available in one place.
- Peril: The flexibility of the data lake is also its greatest weakness. Without rigorous, proactive governance, data lakes frequently devolve into "data swamps"—disorganized, poorly documented, and untrustworthy repositories where data quality is abysmal. In this state, finding and preparing data for AI becomes nearly impossible, and the repository becomes a liability rather than an asset. Furthermore, the centralized nature of the data lake can create a significant organizational bottleneck, with a single central data team struggling to serve the diverse and growing needs of the entire enterprise, leading to delays and frustrated data science teams.
Architecture 2: The Hybrid Data Lakehouse
The data lakehouse represents a significant architectural evolution, designed to merge the best attributes of data lakes and data warehouses. It combines the low-cost, scalable storage and flexibility of a data lake with the reliability, strong governance, and performance of a data warehouse. Platforms like Databricks have pioneered this approach.
- Promise for AI: The lakehouse provides a single, unified platform for all data, analytics, and AI workloads, eliminating the need to move and duplicate data between different systems. It supports ACID (atomicity, consistency, isolation, durability) transactions, which ensures a high degree of data integrity and reliability—a critical requirement for training trustworthy AI models. By design, this architecture is AI-ready, allowing data scientists to seamlessly join structured business data with unstructured data like text and images within a single, governed environment, dramatically streamlining workflows and reducing data duplication.
Architecture 3: The Decentralized Data Mesh
The data mesh is not just a new architecture; it is a paradigm shift in thinking about enterprise data. It fundamentally rejects the centralized, monolithic approach of the data lake and lakehouse in favor of a decentralized, distributed architecture organized around business domains (e.g., marketing, sales, supply chain). This approach is founded on four core principles articulated by Zhamak Dehghani:
- Domain-Oriented Ownership: Data ownership is decentralized and aligned with business domains. The teams that are closest to the data and understand its context best are responsible for it.
- Data as a Product: Each domain is responsible for treating its data as a product, which it serves to the rest of the organization. This means the data must be discoverable, addressable, trustworthy, and well-documented.
- Self-Serve Data Platform: A central platform team provides the common tools and infrastructure that enable domain teams to build, deploy, and manage their data products autonomously.
- Federated Computational Governance: A central governance body sets global standards and policies, but these rules are automated and embedded within the self-serve platform, allowing domains to operate with autonomy while ensuring enterprise-wide interoperability and security.
- Promise for AI: The data mesh is designed to handle the complexity and scale of large, modern enterprises. By empowering domain experts to own their data products, it dramatically improves data quality, context, and trustworthiness. This democratizes data access for data science and analytics teams, allowing them to directly discover and consume high-quality, analysis-ready "data products" without going through a central bottleneck. For AI applications, this is transformative. It provides a steady stream of reliable, well-understood data that is critical for building accurate models and, particularly for large language models (LLMs), reducing the risk of "hallucinations" by grounding them in high-fidelity, domain-curated data.
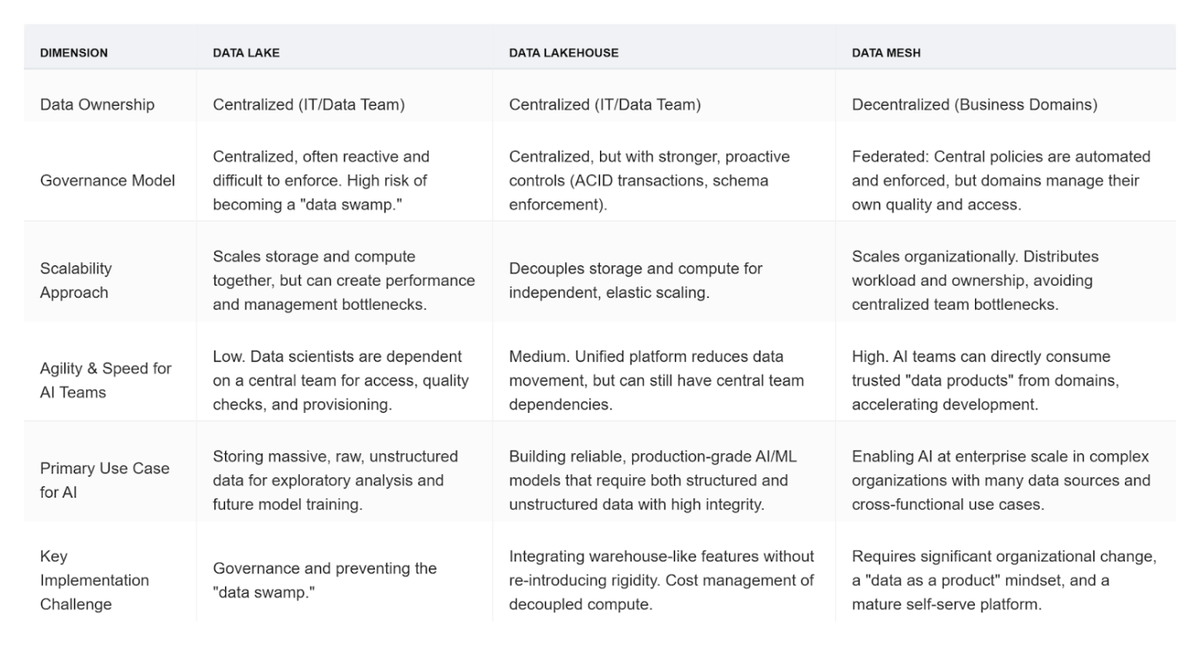
Strategic Comparison of Data Architectures for Enterprise AI
To aid in strategic decision-making, the following table provides a high-level comparison of these three architectural approaches across key dimensions relevant to enterprise AI initiatives.
4. The Governance Imperative: Building a Framework for Trusted, Responsible AI
In the context of AI, data governance must be reframed. It is not a restrictive, compliance-driven checklist that slows down innovation, but rather the strategic enabler of trusted, scalable, and responsible AI. A mature data and analytics (D&A) governance program is one of the strongest predictors of an organization's ability to adopt data-driven innovations. Strong governance builds the foundation of trust and reliability necessary for business stakeholders to confidently adopt and champion AI solutions. Without it, AI remains a high-risk experiment. This imperative is underscored by a Gartner prediction that by 2027, 60% of organizations will fail to realize the expected value of their AI use cases due to incohesive ethical governance frameworks.
A critical challenge for modern organizations is the recursive nature of AI governance. On one hand, high-quality, well-governed data is an absolute prerequisite for building reliable AI models—this is "governance for AI". On the other hand, the sheer volume, velocity, and complexity of modern data make purely manual governance impossible. Organizations require AI-powered tools to automate data quality monitoring, policy enforcement, and cataloging at scale—this is "AI for governance". This creates a "chicken-and-egg" dilemma that can paralyze progress. The solution is not to solve one problem completely before starting the other, but to pursue an iterative, evolutionary path. Organizations must begin by establishing foundational, often manual, governance practices on their most critical data assets. This initial "good enough" data can then be used to train basic AI-powered governance tools. The insights and automation from these tools, in turn, help improve a wider set of data, which then allows for the development of more sophisticated AI governance capabilities. This creates a virtuous cycle—a "governance flywheel"—that gradually matures both the data foundation and the governance program in tandem.
Best Practices for Modern AI Governance
To build a governance framework that can power this flywheel, organizations should adopt a set of modern best practices that are both comprehensive and adaptable.
- Establish Clear Ownership and Accountability: Effective governance begins with clear lines of responsibility. This requires moving beyond simply assigning governance to an existing IT team and instead building a dedicated, cross-functional governance body that includes data scientists, business leaders, compliance officers, and legal experts. Within this structure, clear roles must be defined, such as Data Owners, who are senior leaders accountable for the data within a specific business domain, and Data Stewards, who are responsible for the day-to-day management of data quality, access, and compliance.
- Implement a Data Quality Framework: This framework is the operational heart of the governance program. It is a documented set of principles, standards, rules, and tools used to consistently measure, monitor, and improve the health of data assets. For AI, this framework must address a multidimensional view of data quality, including not only traditional metrics like accuracy, completeness, consistency, and timeliness, but also AI-specific dimensions such as relevance, validity, and, critically, fairness to detect and mitigate bias.
- Integrate Responsible AI Principles: AI governance must extend beyond technical data quality to encompass the broader ethical implications of model development and deployment. This requires embedding core principles of responsible AI directly into the governance framework. Key principles include:
- Fairness and Bias Mitigation: Proactively testing for and mitigating biases in data and models to ensure equitable outcomes.
- Transparency and Explainability: Ensuring that AI decision-making processes are understandable and can be scrutinized, moving away from "black box" models where possible.
- Privacy and Data Protection: Implementing robust security and privacy protocols to safeguard sensitive data and comply with regulations.
- Leverage Automation and AI for Governance: As data landscapes grow to include thousands of sources, manual governance becomes infeasible. A modern framework must leverage technology to scale. This includes using AI-powered tools to automate critical governance tasks such as data discovery and cataloging, continuous data quality monitoring, anomaly detection, and the enforcement of access and privacy policies. Automation makes governance proactive rather than reactive, flagging issues before they impact downstream AI models.
- Foster a Data-Driven Culture: Ultimately, governance is not just about policies and tools; it is about changing behavior. A successful governance program requires a concerted effort to foster a data-driven culture throughout the organization. This involves investing in continuous training and data literacy programs to ensure that all employees—from senior executives to frontline analysts—understand the strategic value of well-managed data and recognize their individual role in upholding data quality and governance standards.
5. The Flywheel Effect: Accelerating Time-to-Value with Data Pipeline Automation

The data pipeline is the circulatory system of any AI initiative. It is the complex set of processes that automates the flow of data from raw collection to model training and deployment, encompassing critical steps like data ingestion, cleaning, transformation, feature engineering, and loading into machine learning models. The efficiency and reliability of this pipeline directly determine the speed and success of AI development. A slow, brittle, or unreliable pipeline acts as a major constraint, while a fast, robust, and automated pipeline becomes a powerful accelerator—a flywheel for AI innovation.
A data-centric AI strategy, by its very nature, is an iterative process of continuous data improvement: train a model, analyze its errors, improve the data, and repeat the cycle. This iterative loop is only practical at an enterprise scale if the underlying data pipelines are automated. Each "improve the data" step—whether it involves adding a new cleaning rule, transforming a feature, or augmenting a specific data subset—requires a change to the pipeline. If each of these changes is a manual, multi-week effort requiring significant data engineering resources, the feedback loop becomes too slow to be effective. A data scientist might identify a critical data issue, but by the time the pipeline is manually updated, the business context may have already shifted. Data pipeline automation is the operational engine that allows this DCAI loop to spin fast enough to deliver value, enabling data scientists and domain experts to rapidly and reliably implement data improvements without being bottlenecked by engineering backlogs.
The Inefficiency of Manual Pipelines
Historically, data pipelines were built using manual scripting and a patchwork of disparate tools. This approach is no longer viable in the modern data landscape. Manual and scripted pipelines are notoriously brittle; a small change in a source data format can cause the entire pipeline to fail silently. They are also incredibly labor-intensive, requiring immense data engineering effort to build, debug, maintain, and update. This inefficiency creates a significant drag on AI projects, consuming valuable resources and introducing long delays that stifle innovation.
The Power of Automation
Modern data pipeline automation platforms provide an intelligent control layer that centralizes and autonomously orchestrates the entire data workflow, from source to consumption. By consolidating all steps within a single, unified interface, these platforms deliver transformative benefits:
- Productivity and Speed: Automation can reduce the engineering effort required to produce analytics-ready data by as much as 90%. This frees up data teams from low-level debugging and maintenance, allowing them to focus on higher-value activities like collaborating with business stakeholders and developing new data products.
- Cost Reduction: By intelligently managing and optimizing data processing, automation eliminates redundant computations and reduces wasted cloud resources. Organizations have reported a 30% or greater reduction in cloud computing costs for data transformation and processing after implementing these platforms.
- Consistency and Reliability: Automation eliminates the risk of human error, which is a common source of data quality issues and pipeline failures. It ensures that data is processed consistently and reliably every time. Furthermore, automated data quality rules and checks can be embedded at every stage of the pipeline, automatically flagging or quarantining bad data before it can corrupt an AI model.
AI-Powered Automation: The Next Frontier
The most advanced automation platforms are now incorporating AI to manage and optimize the pipelines themselves, creating a self-improving system that acts as a true flywheel.
- Predictive Maintenance: Machine learning models are used to analyze historical pipeline performance data and system metrics to anticipate potential failures before they occur. These systems can identify patterns that precede common issues like resource bottlenecks or API timeouts, enabling proactive interventions that ensure a reliable, uninterrupted flow of high-quality data to production AI systems.
- Self-Optimizing Performance: AI algorithms continuously monitor pipeline performance metrics such as data volume and transformation complexity. Based on this real-time feedback, they can dynamically adjust processing parameters—such as repartitioning tasks or modifying resource allocation—to ensure the pipeline maintains peak efficiency as data volumes grow and business requirements evolve.
- Generative AI for Pipeline Development: A new frontier in automation involves using generative AI to accelerate pipeline creation. These tools can analyze business requirements expressed in natural language and automatically generate optimized, high-quality code for common data transformation and integration tasks, dramatically reducing development time and ensuring adherence to best practices.
6. From Foundation to Financials: Real-World Success and Quantifiable ROI
The strategic imperative to invest in a robust data foundation is ultimately validated by its impact on the bottom line. The true return on investment (ROI) of this foundational work should not be measured against a single AI project but as a platform-level multiplier that reduces the marginal cost and time for every subsequent AI initiative. A strong data foundation transforms AI development from a series of expensive, one-off artisanal projects into a scalable, repeatable industrial process—an "AI factory" where the data foundation serves as the assembly line. The following real-world examples and quantifiable metrics provide compelling evidence that connects a well-engineered data foundation directly to accelerated business value, improved efficiency, and enhanced financial performance.
Metric 1: Faster Time-to-Value
A primary benefit of a solid data foundation is the dramatic acceleration of AI project timelines. By eliminating the data wrangling, integration, and quality issues that plague most initiatives, organizations can move directly from concept to value creation.
- Evidence: Enterprises that deploy AI-guided adoption strategies built on a strong data foundation see up to 3x faster time-to-value compared to those with static, poorly integrated data systems. This is echoed by marketing technology providers who have demonstrated a 3x faster time to value by ensuring data is clean and accessible from the start. A global fintech enterprise, by focusing on a scalable architecture and creating AI-ready teams, successfully transformed its generative AI vision into a production-grade innovation studio in just 90 days.
Metric 2: Improved Operational Efficiency and Cost Savings
Clean, accessible, and integrated data allows AI to automate complex processes, optimize resource allocation, and deliver insights that drive significant operational efficiencies and cost reductions.
- Domina, a Colombian logistics company, built an AI-powered platform on a unified data foundation to predict package returns and automate delivery validation. The results were a 15% increase in delivery effectiveness, an 80% improvement in real-time data access, and the complete elimination of time spent on manual report generation.
- Johns Hopkins Hospital implemented an AI-powered control center that integrated real-time bed availability data with patient clinical data. This system allowed the hospital to assign beds 30% faster, reduce wait times for emergency room patients by 20%, and cut the need to hold surgery patients in recovery rooms by 80%.
- Woven (Toyota), by building its autonomous driving development platform on a modern data architecture, achieved a 50% reduction in total-cost-of-ownership.
- A Forrester Total Economic Impact study of a composite organization using a modern security operations platform built on unified data found a 240% ROI over three years, with a net present value of $4.3 million.
Metric 3: Enhanced Model Performance and Direct Business Impact
Ultimately, the quality of the data foundation translates directly into the accuracy of AI models, which in turn drives measurable business outcomes such as revenue growth, cost reduction, and competitive advantage. Research from Harvard Business Review confirms that "data-to-value leaders"—organizations with a strong data foundation—significantly outperform their peers in profitability, market share, and customer satisfaction.
- Moglix, an Indian digital supply chain platform, deployed a generative AI vendor discovery tool on its data platform. This led to a 4x improvement in sourcing team efficiency, directly contributing to a quarterly business increase from approximately INR 12 crore to 50 crore.
- Miinto, an e-commerce marketplace, used an AI vision model to identify and merge duplicate product listings from its partners. By cleaning its product data at scale, the company achieved a 40% increase in operational efficiency and, critically, a 20% improvement in customer conversion rates.
- American Express leverages its high-quality transaction data to power machine learning-based fraud detection models that prevent over $2 billion in fraudulent losses annually.
- An aerospace manufacturer faced frequent communication failures with its satellites, a problem rooted in low-quality, disparate data sources. By adopting a data-centric approach using programmatic labeling to systematically improve the data, the company was able to build a highly effective AI-based failure detection tool, turning a data roadblock into a high-value operational asset.
These cases provide definitive proof of the report's central thesis: a strategic investment in the data foundation is not a preliminary chore but the primary driver of AI success and financial return.
Conclusion: A Blueprint for Your AI-Ready Data Foundation

The journey to enterprise AI success begins and ends with data. The AI Value Paradox—the frustrating gap between widespread AI adoption and elusive organizational transformation—is not an unsolvable enigma. It is a direct result of a strategic misstep: focusing on the allure of advanced models while neglecting the foundational engineering of the data that fuels them. The evidence presented in this report is unequivocal: organizations that systematically build a robust, reliable, and well-governed data foundation are the ones that unlock the true transformative potential of AI, achieving faster time-to-value, greater operational efficiency, and a sustainable competitive advantage.
For executives and strategic consultants charting the course for their organizations, the path forward requires a deliberate and disciplined approach. The following blueprint provides a high-level, strategic roadmap to guide this critical transformation.
An Actionable Blueprint for Executives
- Assess Your Data Debt: The first step is a candid and comprehensive audit of your organization's data maturity. The critical question is not "Are we ready for AI?" but rather "Where are our most significant data governance, quality, and accessibility gaps?" This assessment must go beyond IT systems to evaluate the cultural and process-related challenges that create and perpetuate data debt.
- Champion a Data-Centric Culture: The shift to a data-centric mindset is a leadership challenge, not a technical one. It requires executive champions who can articulate a compelling vision for data as a core business product, not merely an IT asset. This involves redefining roles, creating incentives for cross-functional collaboration, and investing in enterprise-wide data literacy to build a culture of shared accountability for data quality.
- Make a Strategic Architectural Choice: The selection of a data architecture is a long-term strategic decision that must align with the organization's scale, complexity, and cultural readiness. Evaluate the merits of Data Lakes, Data Lakehouses, and the Data Mesh not as competing technologies, but as different operating models for enterprise data. The choice will reflect and shape your organization's ability to innovate with agility and at scale.
- Invest in Governance and Automation as a Unit: Treat data governance frameworks and data pipeline automation platforms as two sides of the same coin. They must be planned, funded, and implemented together. Robust governance provides the "what"—the rules, standards, and policies for trusted data. Advanced automation provides the "how"—the scalable, efficient, and reliable means to enforce those standards across the enterprise. One without the other is insufficient for enabling trusted AI at scale.
The investment in a data foundation should not be viewed as a cost center or a preliminary chore to be rushed through. It is the single most critical strategic investment an organization can make to ensure it not only survives but thrives in the age of AI. It is the hidden key that unlocks sustainable, long-term value and turns the promise of artificial intelligence into a tangible business reality.
Visit Alpha Technical Solutions to learn more and book a free strategy discussion, and let us help you transform the promise of AI into a tangible business reality.